

Quick summary
Summarize this blog with AI
Introduction
In my previous article, “Django for Data Scientists Part I: Serving A Machine Learning Model through a RESTFul API, I showed you how to serve a machine learning classification model through your local machine and handle API requests. Now, let’s move on one step further. I want to show you how to deploy that model into a productionized environment into Heroku and server the model to the whole internet.
In the end, you will have a restful API endpoint that listens to a get request from the internet (instead of your local laptop) which allows other people to submit an input sample and get a predicted result.
We've created a crash course to teach you everything covered in this article with 1 hour long, 8 video lectures. Feel free to check out the course here.
If you wanted to follow my step by step tutorials, grab a ☕️ and let’s get started:
Step 1: set up your project
The following step-by-step instructions are for Mac users. Please feel free to ping me if the code has any issues for Linux or other operating systems. I assume you have a reasonable amount of knowledge about python and machine learning, and I will skip explanations of the model training process. We will be using a Heroku Django template https://github.com/heroku/heroku-django-template to jumpstart the project.
[projects]$ django-admin.py startproject --template=https://github.com/heroku/heroku-django-template/archive/master.zip --name=Procfile heroku_classification_model[projects]$ cd heroku_classification_model
[heroku_classification_model]$ ls
Pipfile README.md manage.py
Procfile heroku_classification_modelYou should see the above files and directories at the root of your project.
The psycopg2 library included in this template doesn’t work for me on my local computer, so instead of using the Pipfile to install dependent libraries, let’s remove the Pipfile and create our own requirements.txt file.
# Removing existing Pipfile
[heroku_classification_model]$ rm Pipfile
# Create a Python 3 virtual environment and name it venv
[heroku_classification_model]$ python3 -m venv venv
# Activate the virtual environment
[heroku_classification_model]$ source venv/bin/activateUnder the project's root, create a requirements.txt file, copy and paste the following content into it and save the file.
asgiref==3.2.3
dj-database-url==0.5.0
Django==3.0.4
django-heroku==0.3.1
joblib==0.14.1
numpy==1.18.1
psycopg2==2.8.4
pytz==2019.3
scikit-learn==0.22.2.post1
scipy==1.4.1
sqlparse==0.3.1
whitenoise==5.0.1
gunicorn==20.0.4Now let’s install the dependency python libraries.
(venv) [heroku_classification_model]$ pip install -r requirements.txtLet’s try to start the dev server locally.
(venv) [heroku_classification_model]$ python manage.py runserverIf you open your browser and go to http://127.0.0.1:8000/, you should see something like the following:

Django Development server on your local machine
Step 2: Create a Django app to serve our machine learning model:
(venv) [heroku_classification_model]$ django-admin startapp modeling
(venv) [heroku_classification_model]$ cd modeling/
(venv) [modeling]$ ls
__init__.py admin.py apps.py migrations models.py tests.py views.pyNow we need to add the ‘modeling’ app to the installed apps in the project settings.py file, which is located at heroku_classification_model/settings.py
Register newly installed modeling app to project’s settings.py file.
Step 3: Training a sentiment classification model based on movie reviews
Let’s go to the newly install app folder:
(venv) [heroku_classification_model]$ cd modeling/Now let’s prepare some training data. Execute the following script after launching your python console. The original script can be found on scikit-learn’s official GitHub page here:
import os
import tarfile
from contextlib import closing
try:
from urllib import urlopen
except ImportError:
from urllib.request import urlopenURL = ("http://www.cs.cornell.edu/people/pabo/"
"movie-review-data/review_polarity.tar.gz")ARCHIVE_NAME = URL.rsplit('/', 1)[1]
DATA_FOLDER = "txt_sentoken"if not os.path.exists(DATA_FOLDER):
if not os.path.exists(ARCHIVE_NAME):
print("Downloading dataset from %s (3 MB)" % URL)
opener = urlopen(URL)
with open(ARCHIVE_NAME, 'wb') as archive:
archive.write(opener.read())
print("Decompressing %s" % ARCHIVE_NAME)
with closing(tarfile.open(ARCHIVE_NAME, "r:gz")) as archive:
archive.extractall(path='.')
os.remove(ARCHIVE_NAME)After running the above command, there will be a new folder txt_sentoken, that’s where 2000 preprocessed movie review files under two folders: pos (positive reviews) and neg (negative reviews).
Train the model and save the model into a pickle file. We can relaunch python and paste the following code. The original script and detailed explanations can be found here.
import sys
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_files
from sklearn.model_selection import train_test_split
from sklearn import metricsmovie_reviews_data_folder = 'txt_sentoken'
dataset = load_files(movie_reviews_data_folder, shuffle=False)
print("n_samples: %d" % len(dataset.data))docs_train, docs_test, y_train, y_test = train_test_split(
dataset.data, dataset.target, test_size=0.25, random_state=None)pipeline = Pipeline([
('vect', TfidfVectorizer(min_df=3, max_df=0.95)),
('clf', LinearSVC(C=1000)),
])
parameters = {
'vect__ngram_range': [(1, 1), (1, 2)],
}
grid_search = GridSearchCV(pipeline, parameters, n_jobs=-1)
grid_search.fit(docs_train, y_train)Now that the model is trained and parameter fine-tuned through a grid search. Let’s save the best model to serve the incoming requests and making a prediction.
from sklearn.externals import joblibjoblib.dump(grid_search.best_estimator_, 'model.file', compress = 1)Congrats, you now have trained and persisted a sentiment classification model into a binary file locally as ‘model.file’. Now let’s serve the model by creating a local API first.
Open views.py from the modeling app, and add the following code.
from django.shortcuts import render
import osfrom django.http import JsonResponse
from sklearn.externals import joblibCURRENT_DIR = os.path.dirname(__file__)
model_file = os.path.join(CURRENT_DIR, 'model.file')model = joblib.load(model_file)# Create your views here.
def api_sentiment_pred(request):
review = request.GET['review']
result = 'Positive' if model.predict([review]) else 'Negative'
return (JsonResponse(result, safe=False))Now that we have a predict function, we need to create a unique URL as its endpoint. In the modeling folder, create a new urls.py file and enter the following code:
from django.urls import path
from .views import api_sentiment_pred
urlpatterns = [
path('api/predict/', api_sentiment_pred, name='api_sentiment_pred'),
]Now we need to include this URL configuration at the project level. Open heroku_classification_model/settings.py file and replace it with the following contents.
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('model/', include('modeling.urls'))
]Now let’s start the server from the project root.
(venv) [heroku_classification_model]$ python manage.py runserverVisit the following address and pass a test review
http://localhost:8000/model/api/predict/?review=This movie is greatIf everything is running successfully, you will see the predicted sentiment results based on the review “This movie is great”.
"Positive"
Feel free to replace this text with something different and see if you can get any negative sentiment. For example :
http://localhost:8000/model/api/predict/?review=I really don't liked this moviehttp://localhost:8000/model/api/predict/?review=This movie is long and boringAlternatively, you can also use cURL to send a GET request from your command line:
curl 'http://localhost:8000/model/api/predict/?review=This%20movie%20sucks'
"Negative"Congratulations! Now you have successfully created a web server to host your machine learning model on your local machine. It’s time to deploy this model to Heroku so that people can visit your API endpoint from all over the internet.
Step 4: deploying the model to Heroku and serve the model API to THE ENTIRE INTERNET!
Let’s first initialize this project as a git project.
(venv) [heroku_classification_model]$ git init
Initialized existing Git repository in /Users/leon/workspace/projects/heroku_classification_model/.git/(venv) [heroku_classification_model]$ git add .
(venv) [heroku_classification_model]$ git commit -m 'Initialized project'If you don’t have a Heroku account, feel free to set up one. For this tutorial, we only need to use their free tier services. Next, download Heroku's command-line tool using homebrew. If you don’t have homebrew, install it with one line command:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"Then let’s install Heroku CLI.
brew tap heroku/brew && brew install herokuRun Heroku login and set up your account if this is the first time using Heroku. It will prompt you to log in to your Heroku account.
heroku loginNow we are ready to create a new Heroku app, an exciting time!
(venv) [heroku_classification_model]$ heroku create
Creating app... done, ⬢ morning-plains-31313
https://morning-plains-31313.herokuapp.com/ | https://git.heroku.com/morning-plains-31313.gitNotice Heroku automatically created a new app and named it “morning-plains-31313”, your app name will be different than mine. You can now deploy your Heroku app with a simple git command and serve your model to the whole internet, sit tight, and ready to launch. 🚀🔥
(venv) [heroku_classification_model]$ git push heroku masterIt might take several minutes for Heroku to build and deploy your app. Once it’s done, you can try to visit your API endpoint by launching a browser. It is very similar to visit your local API endpoint. For my app, the URL is below, and it will be DIFFERENT than yours.
https://morning-plains-31313.herokuapp.com/model/api/predict/?review=beautiful%20movieYou should see something similar to the following:
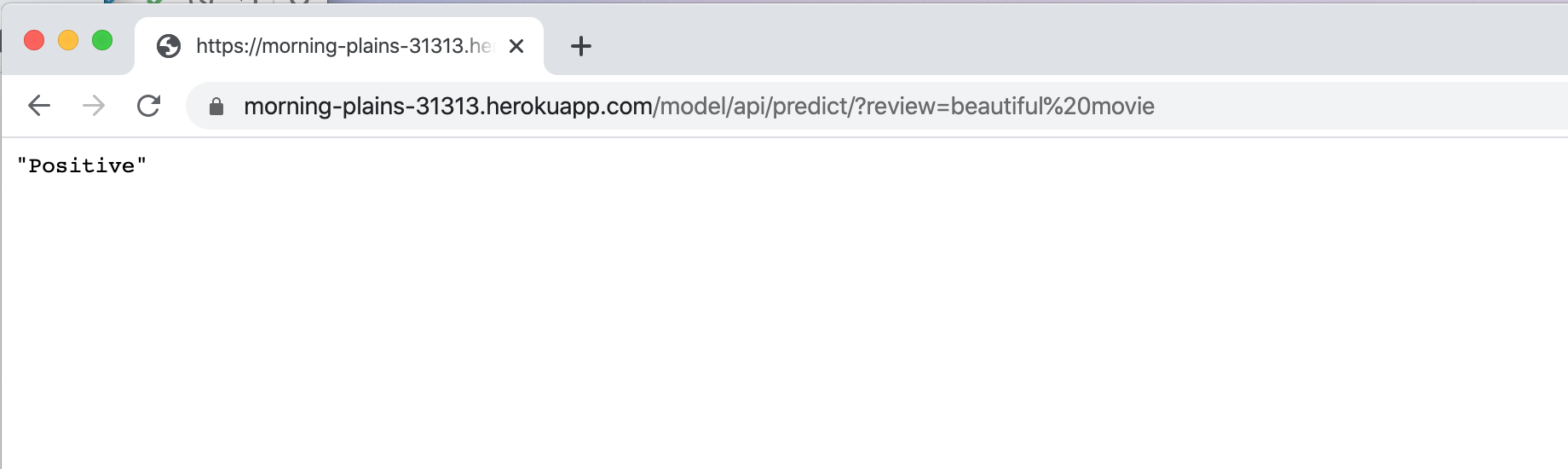
You can also make a get request using cURL:
curl 'http://morning-plains-31313.herokuapp.com/model/api/predict/?review=This%20movie%20sucks'Congrats! Now you’ve deployed a machine learning model, and everyone on the internet can visit it.😎
Summary
In this tutorial: we jumpstarted this project with a Heroku-Django template. We then trained a classification model based on 2000 movie review data;
We then created a local HTTP server, tested the model API on the local machine, did some QA on your local development server, and got ready for production.
Finally, we deployed this project onto Heroku (for totally free), and now the whole internet uses your machine learning service by making a RESTful API call. How cool is that!
We've created a crash course to teach you everything covered in this article with 1 hour long, 8 video lectures. Feel free to check out the course here.


